By Gautam Kamath and Jonathan Ullman
Differentially private statistics is a very lively research area, and has seen a lot of activity in the last couple years. While the phrasing is a slight departure from previous work which focused on estimation with worst-case datasets, it turns out that the differences are often superficial. In a short series of blog posts, we hope to educate readers on some of the recent advancements in this area, as well as shed light on some of the connections between the old and the new. We’ll describe the settings, cover a couple of technical examples, and give pointers to some other directions in the area. Thanks to Adam Smith for helping kick off this project, Clément Canonne, Aaron Roth, and Thomas Steinke for helpful comments, and Luca Trevisan for his LaTeX2WP script.
1. Introduction
Statistics and machine learning are now ubiquitous in data analysis. Given a dataset, one immediately wonders what it allows us to infer about the underlying population. However, modern datasets don’t exist in a vacuum: they often contain sensitive information about the individuals they represent. Without proper care, statistical procedures will result in gross violations of privacy. Motivated by the shortcomings of ad hoc methods for data anonymization, Dwork, McSherry, Nissim, and Smith introduced the celebrated notion of differential privacy [DMNS06].
From its inception, some of the driving motivations for differential privacy were applications in statistics and the social sciences, notably disclosure limitation for the US Census. And yet, the lion’s share of differential privacy research has taken place within the computer science community. As a result, the specific applications being studied are often not formulated using statistical terminology, or even as statistical problems. Perhaps most significantly, much of the early work in computer science (though definitely not all) focus on estimating some property of a dataset rather than estimating some property of an underlying population.
Although the earliest works exploring the interaction between differential privacy and classical statistics go back to at least 2009 [VS09,FRY10], the emphasis on differentially private statistical inference in the computer science literature is somewhat more recent. However, while earlier results on differential privacy did not always formulate problems in a statistical language, statistical inference was a key motivation for most of this work. As a result many of the techniques that were developed have direct applications in statistics, for example establishing minimax rates for estimation problems.
The purpose of this series of blog posts is to highlight some of those results in the computer science literature, and present them in a more statistical language. Specifically, we will discuss:
- Tight minimax lower bounds for privately estimating the mean of a multivariate distribution over
, using the technique of tracing attacks developed in [BUV14,DSSUV15, BSU17, SU17a, SU17b, KLSU19].
- Upper bounds for estimating a distribution in Kolmogorov distance, using the ubiquitous binary-tree mechanism introduced in [DNPR10,CSS11].
In particular, we hope to encourage computer scientists working on differential privacy to pay more attention to the applications of their methods in statistics, and share with statisticians many of the powerful techniques that have been developed in the computer science literature.
1.1. Formulating Private Statistical Inference
Essentially every differentially private statistical estimation task can be phrased using the following setup. We are given a dataset 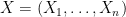


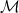
- differentially private, and
- accurate, either in expectation or with high probability, according to some task-specific measure.
A few comments about this framework are in order. First, although the accuracy requirement is stochastic in nature (i.e., an algorithm might not be accurate depending on the randomness of the algorithm and the data generation process), the privacy requirement is worst-case in nature. That is, the algorithm must protect privacy for every dataset 
Second, the accuracy requirement is stated rather vaguely. This is because the notion of accuracy of an algorithm is slightly more nuanced, depending on whether we are concerned with empirical or population statistics. A particular emphasis of these blog posts is to explore the difference (or, as we will see, the lack of a difference) between these two notions of accuracy. The former estimates a quantity of the observed dataset, while the latter estimates a quantity of an unobserved distribution which is assumed to have generated the dataset.
More precisely, the former can be phrased in terms of empirical loss, of the form:
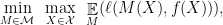
where 


In contrast, statistical minimax theory looks at statements about population loss, of the form:
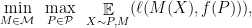
where 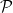

These two formulations are formally very different in several ways. First, the empirical formulation requires an estimator to have small loss on worst-case datasets, whereas the statistical formulation only requires the estimator to have small loss on average over datasets drawn from certain distributions. Second, the statistical formulation requires that we estimate the unknown quantity 

However, in practice (more precisely, in the practice of doing theoretical research), these two formulations are more alike than they are different, and results about one formulation often imply results about the other formulation. On the algorithmic side, classical statistical results will often tell us that 

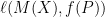
Moreover, typical lower bound arguments for empirical quantities are often statistical in nature. These typically involving constructing some simple “hard distribution” over datasets such that no private algorithm can estimate well on average for this distribution, and thus these lower bound arguments also apply to estimating population statistics for some simple family of distributions. We will proceed to give some examples of estimation problems that were originally studied by computer scientists with the empirical formulation in mind. These results either implicitly or explicitly provide solutions to the corresponding population versions of the same problems—our goal is to spell out and illustrate these connections.
2. DP Background
Let 



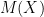
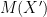

Definition 1 ([DMNS06]) A mechanism
is
-differentially private if for every pair of adjacent datasets


We let 
Remark 1 To simplify notation, and to maintain consistency with the literature, we adopt the convention of defining the mechanism only for a fixed sample size
Remark 2 In these blog posts, we stick to the most general formulation of differential privacy, so-called approximate differential privacy, i.e.
essentially because this is the notion that captures the widest variety of private mechanisms. Almost all of what follows would apply equally well, with minor technical modifications, to slightly stricter notions of concentrated differential privacy [DR16, BS16, BDRS18], Rényi differential privacy [Mir17], or Gaussian differential privacy [DRS19]. While so-called pure differential privacy, i.e.
-differential privacy has also been studied extensively, this notion is artificially restrictive and excludes many differentially private mechanisms.
A key property of differential privacy that helps when desinging efficient estimators is closure under postprocessing:
Lemma 2 (Post-Processing [DMNS06]) If
is any randomized algorithm, then
is
The estimators we present in this work will use only one tool for achieving differential privacy, the Gaussian Mechanism.
Lemma 3 (Gaussian Mechanism) Let
be a function and let
denote its
-sensitivity. The Gaussian mechanism
satisfies
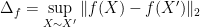

3. Mean Estimation in
Let’s take a dive into the problem of private mean estimation for some family ![{[\pm 1]^d}](https://s0.wp.com/latex.php?latex=%7B%5B%5Cpm+1%5D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)

Note that, by a simple argument, the non-private minimax rate for this class is achieved by the empirical mean, and is

The main goal of this section is to derive the minimax bound
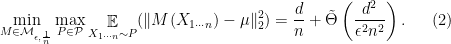
Recall that 




Remark 3 The choice of
in (2) may look strange at first. For the upper bound this choice is arbitrary—as we will see, we can upper bound the rate for any
. The lower bound applies only when
. Note that the rate is qualitatively different when
. However, we emphasize that
. In particular, the mechanism that randomly outputs
elements of the sample satisfies
-differential privacy. However, when
person in the dataset. Moreover, taking the empirical mean of these
, which would violate our lower bound when
3.1. A Simple Upper Bound
Theorem 4 For every
, and every
, there exists an

Proof: Define the mechanism

This mechanism satisfies 


Let 




3.2. Minimax Lower Bounds via Tracing
Theorem 5 For every
,
, and
, if
, then for some constant
,

Note that it is trivial to achieve error 


Tracing Attacks.
Before giving the formal proof, we will try to give some intuition for the high-level proof strategy. The proof can be viewed as constructing a tracing attack [DSSU17] (sometimes called a membership inference attack) of the following form. There is an attacker who has the data of some individual 

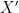
Thus, the proof works by constructing a test statistic 

Proof of Theorem 5.
The proof that we present closely follows the one that appears in Thomas Steinke’s Ph.D. thesis [Ste16].
We start by constructing a “hard distribution” over the family of product distributions ![{\mu = (\mu^1,\dots,\mu^d) \in [-1,1]^d}](https://s0.wp.com/latex.php?latex=%7B%5Cmu+%3D+%28%5Cmu%5E1%2C%5Cdots%2C%5Cmu%5Ed%29+%5Cin+%5B-1%2C1%5D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-1,1]}](https://s0.wp.com/latex.php?latex=%7B%5B-1%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
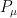


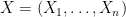
Let ![{M \colon \{\pm 1\}^{n \times d} \rightarrow [\pm 1]^d}](https://s0.wp.com/latex.php?latex=%7BM+%5Ccolon+%5C%7B%5Cpm+1%5C%7D%5E%7Bn+%5Ctimes+d%7D+%5Crightarrow+%5B%5Cpm+1%5D%5Ed%7D&bg=ffffff&fg=000000&s=0&c=20201002)
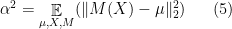
be its expected loss. We will prove the desired lower bound on 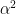
For every element 

where 



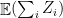

The first claim says that, when 
 ,
,  , and
, and  .
. Proof: Conditioned on any value of 


For the second part of the claim, since 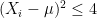
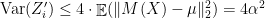

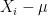


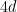
The next claim says that, because 
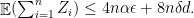
Proof: The proof is a direct calculation using the following inequality, whose proof is relatively simple using the definition of differential privacy:

Given the inequality and Claim 1, we have

The claim now follows by summing over all
The final claim says that, because

The proof relies on the following key lemma, whose proof we omit.
Lemma 6 (Fingerprinting Lemma [BSU17]) If
is sampled uniformly,
are sampled independently with mean
is any function, then
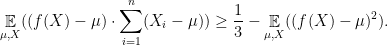
The lemma is somewhat technical, but for intuition, consider the case where 
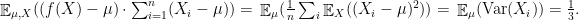
The lemma says that, when 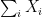
We now prove Claim 3.
Proof: We can apply the lemma to each coordinate of the estimate

The inequality is Lemma 6.
Combining Claims 2 and 3 gives

Now, if 

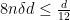

Combining the two cases for 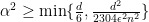
Bibliography
[BDRS18] Mark Bun, Cynthia Dwork, Guy N. Rothblum, and Thomas Steinke. Composable and versatile privacy via truncated CDP. STOC ’18.
[BS16] Mark Bun and Thomas Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. TCC ’16-B.
[BSU17] Mark Bun, Thomas Steinke, and Jonathan Ullman. Make up your mind: The price of online queries in differential privacy. SODA ’17.
[BUV14] Mark Bun, Jonathan Ullman, and Salil Vadhan. Fingerprinting codes and the price of approximate differential privacy. STOC ’14.
[CSS11] T-H Hubert Chan, Elaine Shi, and Dawn Song. Private and continual release of statistics. ACM Transactions on Information and System Security, 14(3):26, 2011.
[CWZ19] T. Tony Cai, Yichen Wang, and Linjun Zhang. The cost of privacy: Optimal rates of convergence for parameter estimation with differential privacy. arXiv, 1902.04495, 2019.
[DMNS06] Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. TCC ’06.
[DNPR10] Cynthia Dwork, Moni Naor, Toniann Pitassi, and Guy N. Rothblum. Differential privacy under continual observation. STOC ’10.
[DR16] Cynthia Dwork and Guy N. Rothblum. Concentrated differential privacy. arXiv, 1603.01887, 2016.
[DRS19] Jinshuo Dong, Aaron Roth, and Weijie J. Su. Gaussian differential privacy. arXiv, 1905.02383, 2019.
[DSSU17] Cynthia Dwork, Adam Smith, Thomas Steinke, Jonathan Ullman, and Salil Vadhan. Robust traceability from trace amounts. FOCS ’15.
[DSSUV15] Cynthia Dwork, Adam Smith, Thomas Steinke, and Jonathan Ullman. Exposed! a survey of attacks on private data. Annual Review of Statistics and Its Application, 4:61–84, 2017.
[FRY10] Stephen E. Fienberg, Alessandro Rinaldo, and Xiaolin Yang. Differential privacy and the risk-utility tradeoff for multi-dimensional contingency tables. PSD ’10.
[KLSU19] Gautam Kamath, Jerry Li, Vikrant Singhal, and Jonathan Ullman. Privately learning high-dimensional distributions. COLT ’19.
[Mir17] Ilya Mironov. Rényi differential privacy. CSF ’17.
[Ste16] Thomas Alexander Steinke. Upper and Lower Bounds for Privacy and Adaptivity in Algorithmic Data Analysis. PhD thesis, 2016.
[SU17a] Thomas Steinke and Jonathan Ullman. Between pure and approximate differential privacy. Journal of Privacy and Confidentiality, 7(2), 2017.
[SU17b] Thomas Steinke and Jonathan Ullman. Tight lower bounds for differentially private selection. FOCS ’17.
[VS09] Duy Vu and Aleksandra Slavković. Differential privacy for clinical trial data: Preliminary evaluations. ICDMW ’09.

One thought on “A Primer on Private Statistics – Part I”